![]()
![]()
![]()
![]()
|
|
|
|
|
After creating a run, the migration collects data about all objects that can be affected by the migration. This data will be stored in the objects_before table. At last, the migration will be collecting these data again and storing those in the objects_after table.
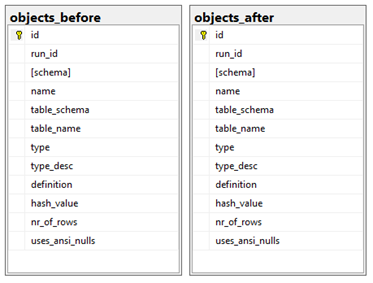
The schema name, the object name, the object type and the type description are stored. The object type is a two-letter abbreviation. The type description shows the same information, but in a more user-friendly format. Most objects, like foreign keys, belong to a table. Therefore, the schema name and table name of this table are also stored. Indexes, for instance do not need to have a unique name in the database, but the indexes belonging to one table need to be uniquely named. Adding the parent table, will make all objects uniquely identifiable. For tables, their fields schema and table_schema and the fields name and table_name will have the same value. Note you cannot use the unique object_id from the sys.objects system table because the migration script drops and recreates objects. Such objects will have a different object_id before and after migration.
The definition field will contain the actual SQL to create the object itself. The hash_value field is a simple CRC value calculated from the definition to enhance the test that checks if the definition before and after the migration are equal. A table definition can be very large. Comparing two large table definitions takes time, whereas comparing two integer values will go quickly.
The fields nr_of_rows and uses_ansi_nulls are only used for objects of the type table. For other objects, these fields will be NULL.
Roughly, the migration of a table contains the following steps:
The data transfer comes in two flavors. If a column existed with the wrong ANSI_PADDING setting, the data is copied from the old to the new table. Otherwise a meta data switch is executed. The data itself is not moved. The pointer of the data only points to the new table definition after the switch. Some version of SQL Server doesn’t store the definition of computed columns in the right format. The computed column will work correctly, but the corrupted definition does block a meta data switch. If a corrupted computed column is found in a table that needs migration, the definition of the computed column will be repaired in the new table. Also a full copy of the data needs to be made. In this case, also, a meta data switch is not possible.
The ANSI_Migration database contains views for easy access of the migration results.
This view shows all objects where:
This view shows all objects that do exist now, but were absent before migration.
If names starting with tmp_ms_sql_server_ show up, an error occurred while transferring of the data to the new table definition. Warning: the old, renamed table does contain the data.
This view shows all objects that existed before migration, but do no longer exist after migration. You can find the create statements of these objects in the definition field of the objects_before table.
This view is a union of the views above.